Calculating set ratings
Posted by Huw,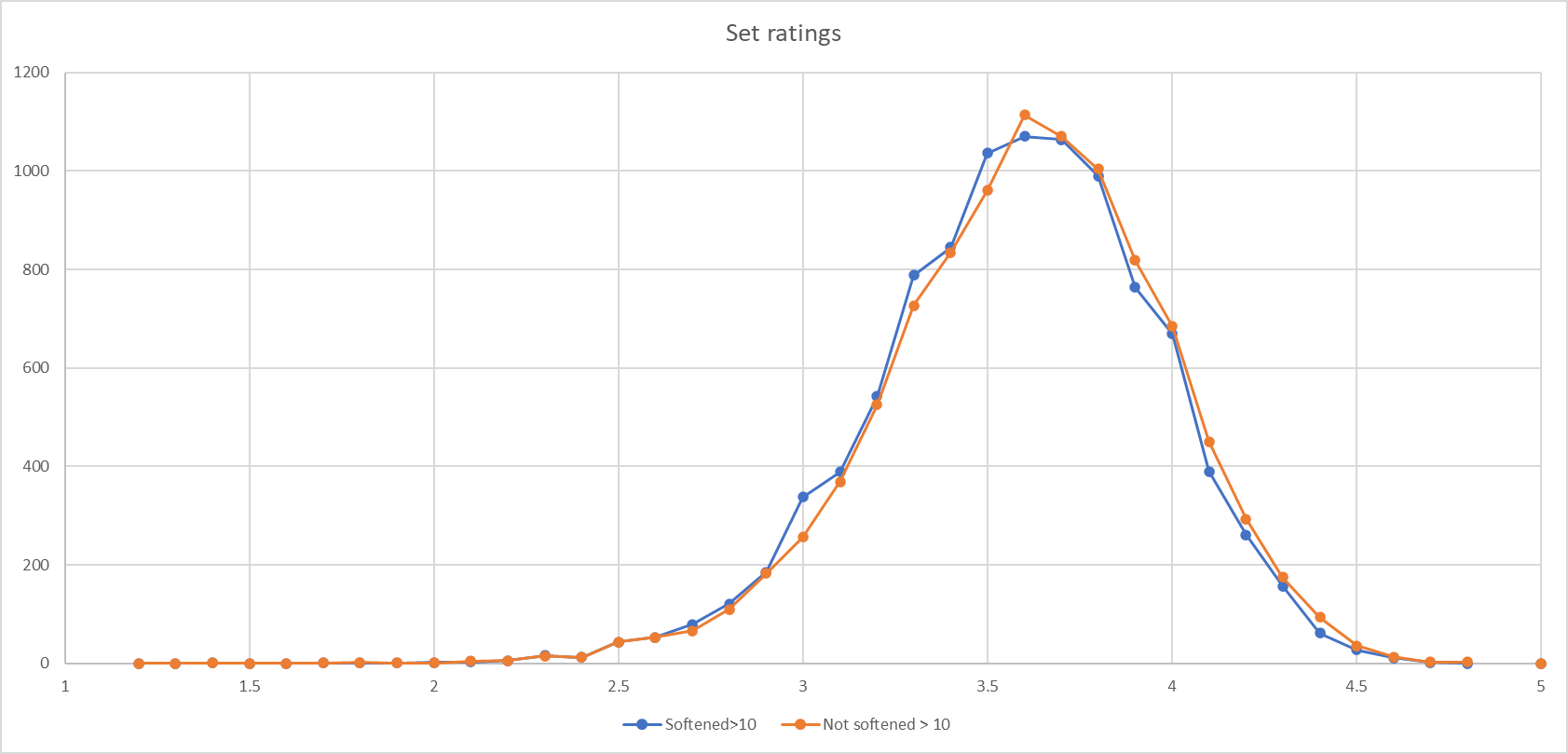
As you will no doubt be aware, Brickset members can review sets and give them a score out of five. These scores are aggregated to give sets an overall rating which are shown as stars in the set listings.
A few years ago I added the ability to rate sets without needing to review them, but they were not taken into account when calculating set ratings.
Mr_Thrawn made the suggestion that they should be, and I agree with that, particularly as there are now almost 1 million ratings in the database, but just 36,000 reviews. We should therefore get more representative figures by doing so, and for more sets. So, your set ratings are now taken into account.
However, there's a problem, and it's not one that's just been introduced by the change: more than three-quarters of all sets have a rating of between 3 and 4, which isn't particularly helpful.
So, I wondered whether any statisticians reading this might be able to help find a solution, and also help answer a question: should a set with 1 rating of five have the same overall rating as one that has 100 ratings of five?
Personally, I think the answer to that question is, no, it shouldn't. One way to make this happen is by using a method that I learned from Lugnet many years ago: add a 'softening' rating of 2.5.
{sum of ratings} + 2.5 / {number of ratings} + 1
So, if a set has one rating of 5, its overall rating with a softener added, is:
5 + 2.5 / 1+1 = 3.75
A set which has 10 ratings of 5:
(5*10 + 2.5) / 10+1 = 4.77
And for a set which has 100 ratings of 5:
(5*100 + 2.5) / 100+1 = 4.97
The overall rating is thus influenced by the individual ratings and the number of them. With no softening score added, all three sets have a rating of 5, of course, but with it, a set can't ever be rated 5. But, surely a set with 100 5's is better than a set with just one?
Softened ratings were shown until I was persuaded to revert to unsoftened ones few years ago. I can't remember why now, but I do think they provide a fairer score, so they are shown in the set listings once again.
Now onto the other problem. Distribution of ratings.
This graph shows the distribution of ratings, with ratings to 1 decimal place on the x-axis and number of sets with that rating on y:
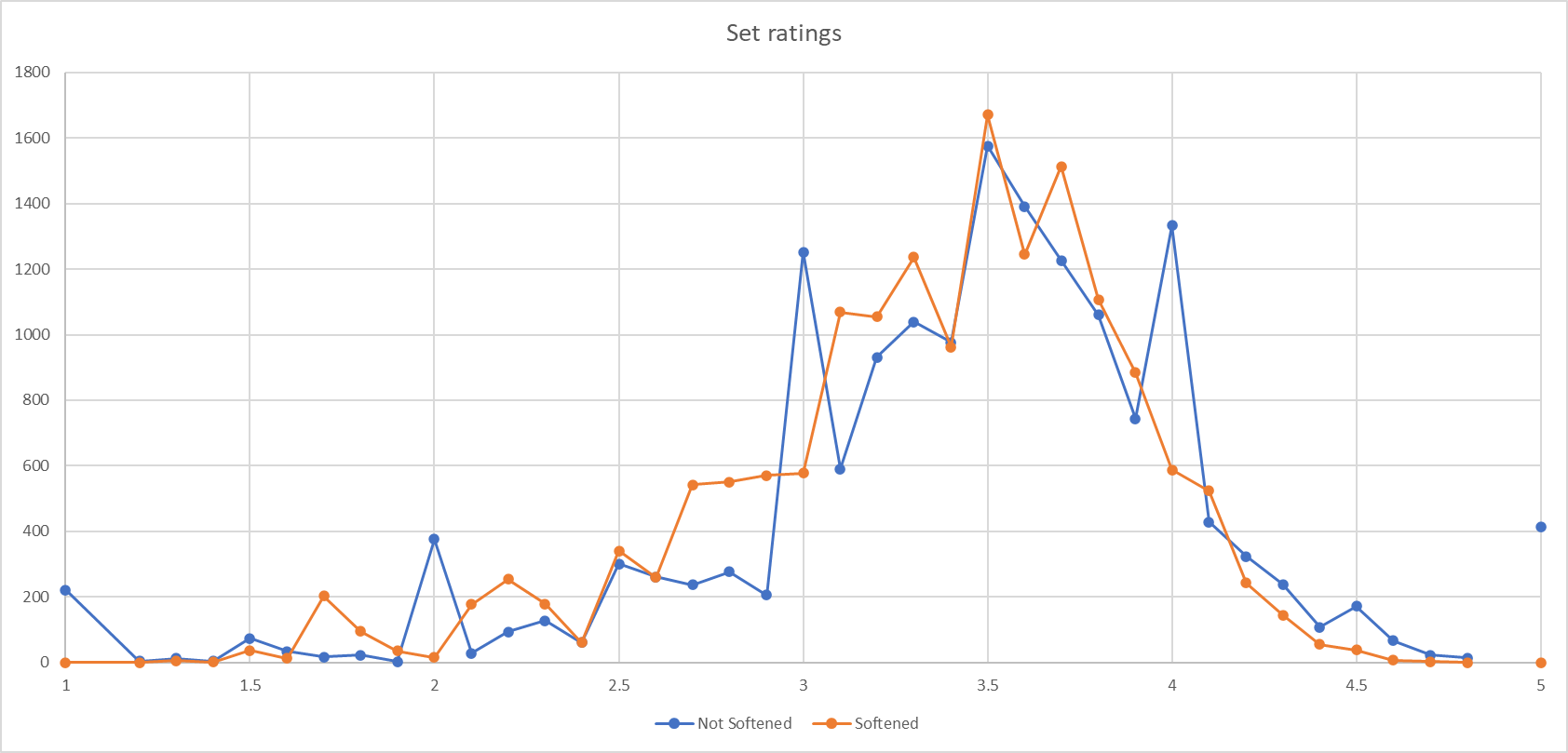
The blue line shows the not softened rating and the orange, the softened one. You can see spikes on the blue line on the integer values, presumably where sets have just one rating or have multiple ratings which are the same.
If sets with fewer than 10 reviews or ratings are excluded from the figures the graph is smoothed out to an almost perfect normal distribution, but skewed to the right. This is probably because people are more likely to rate or review sets they like, and of course they are unlikely to do either if they didn't buy them in the first place because they didn't like them.
The graph also shows that the softener has little impact when there are a lot of ratings.
Of the 16,250 sets with a rating, around 12,000 are rated between 3 and 4, which doesn't seem particularly useful. I guess a perfect scenario would be a flatter and wider distribution centred on 3. I welcome your suggestions as to how this could be achieved, and your opinion on whether it's desirable to do so.
Should ratings be more evenly spread between 1 and 5, or should the majority of sets just be rated mediocre? Should sets with fewer than (say) 10 reviews/ratings not be given an overall rating? Do you agree with the addition of the softener to influence the overall rating of sets with few ratings?
92 likes
65 comments on this article
Would switching to a 10 point system instead of 5 help add the missing granularity? This way the 3/4 star ratings would become a 5 - 9 rating.
Why would you expect a normal distribution centred on 3 as an outcome?
Ignoring any actual user demographics, TLG tries to produce good sets, so there is no reason why you would get an equal number 1 star sets and 5 star sets. Its a skewed set, not like shoe size or heights.
Plus people here like Lego, so will probably overall give good reviews. Also, people will likely only review sets they have, so again have pre-selected a (likely) good set for them.
I agree that sets with low review numbers should be excluded (to avoid spikes as you have shown). Softener to manipulate the data seems a poorer version of a low number filter.
Are people using ratings to compare sets, or just see the overall opinion?
Another solution might be to allow 1-10 to give better granularity between 3 and 4.
Star rating are hard, see XKCD
https://xkcd.com/1098/
but even more https://xkcd.com/937/
Wow, a lot to digest in there :) your dedication and hard work is always very interesting and fun to read. Softened or not will it show how many people have reviewed or rated the set... also could it show "your" rating and what the average "rating" is...for perspective?
For me, most sets are in that middle ground with only occasional outliers being particularly good or particularly bad. Not everything can be a superlative or it looses its meaning. I agree that 100 scores of 5 are more meaningful than just 1 score of 5 but that number of ratings could presumably just be listed as a separate additional figure.
What ever happened to the user review of the week?
I would like to see the variation; how wide the distribution is because it gives an idea how well reviewers agree with each other. A average rating of 3.5 with everyone agreeing would be quite exceptional.
Don't scale the ratings down; people will not adjust their ratings in line with your change.
If the ratings were mapped to some sort of exponential function, that would help spread out the curve. That function could also incorporate the quantity of ratings as a minor factor.
I wish I could read into this more right now, but I have to get back to doing the same thing on my physics homework. :)
Remove the rating or replace it with „would recommend / not recommend this set“. Keep reviews, though. Personal opinions in text form are a lot more informative than a simple star rating.
Also it seems that the number of people owning or wanting a set does say a lot about it’s popularity and that helps me to decide wether I want it or not.
I use the star rating system to organize my wanted list so I can sort my most wanted from my least wanted (on a scale from 5 being most wanted to 1 being least wanted). Also I often unintentionally rate sets while browsing the site. I don't know if others do something similar, but from my experience of ratings (and maybe others), it might not be representative of the actual popularity of the sets.
In music reviews, I find a 10.0 scale more informative than 5 stars (or 5 mics).
IMDb displays the 10.0 scale as well. & their formula can be used, which excludes outliers and has a Minimum threshold of ratings before it can be on ranked lists. Then you could have a top 250 list (or something similar). I’d spend some time digging into the top 100, 250, or 500 set list for sure.
@Legodud9898 said:
"What ever happened to the user review of the week?"
That's what I'm curious about, there was only 2 and from what I saw they where well received from users.
I like the suggestion of adding “recommend” or “Don’t recommend”.
If you use that value to put a multiplier on the rating, you might get what you want. 1.1x if recommended and .9x if not recommended. Who knows... and down side is that would not help with the existing 1 million reviews although either would changing to 10 point scale. I’d bet most users wouldn’t mind re-rating on a 10 point if asked though.
How about only showing the rating if it has X number of ratings, and until that time you can show “Not enough votes” or something like that
@derekthetree said:
" Why would you expect a normal distribution centred on 3 as an outcome?
(...) people here like Lego, so will probably overall give good reviews. Also, people will likely only review sets they have, so again have pre-selected a (likely) good set for them. (...)"
I agree with @derekthetree - it makes sense that the dumbell is dislodged to the higher ratings, otherwise, TLG would be in dire straits. If it wasn't it would be a sign they're failing to design and sell appealling sets - so I see no problem at all with that and wouldn't like to see the data somehow treated in order just to have a perfect distribution.
I do like the softner approach, though, as it doesn't discard information, even when it is sparse. After all, a less-than-10-reviews-set ranked close to 5 might just be appealing to a very niched audience thus, overall, it should rank lower than a set with hundreds of similar reviews - as it is more popular. Perhaps indicating both the final, softned, score along with the number of reviews in total would sufice to give an idea of how good & popular and, therefore, memorable, is a good way to go...
This is the weighted rating system used in some situations (lots of variables, but it's an option!). Couple this with a minimum number of ratings for a set to be ranked and it works well.
S = wR+(1-w)A
where...
S is the weighted "rating" or "score" being computed for a set
R is the average star-rating for the set
A is the average star-rating for ALL sets
w is a weighting, which could be predetermined (like the "softener") but can also be computed like this:
w = v/(v+m)
where v is the number of star-ratings for the set and m is the average number of star-ratings for all sets.
In the end, more star-ratings = a score that is closer to the actual average star-rating given by users. Math is fun!
I think 4 is were I normally rank a lot of sets because I think its a fair value for a set which is pretty good in most of its offerings, but might have some value to be improved such as price or playability or construction. Five star sets really should be reserved for the most astonishing sets, the things that blow my socks off; so if there is signs of something that could have been better I tend to just go for a 4.
Set ownership might be more useful to factor in to the rating adjustment. There must be some correlation between set "goodness" and ownership. It would be informative also to look at ratings vs some other factor such as theme. Maybe among star wars sets a set rates highly, but overall star wars sets are biased higher than other themes by reviewers.
Also factoring into this might be cost - higher price must correlate with lower ownership. These would all be interesting to mix into a score.
To Huw:
One way is to have reviewers rate the set based on a set of criteria (which the system has now) on a scale of 1 to 5 (with meaning assigned to each number to for each criteria, to guide the reviewes i.e. what does a 1 in Playability criteria means vs a 5 in the same criteris), and then amalgamate the ratings of each criteria to arrive at a consolidated rating. Use should not rate overall rating without rating the individual criteria.
Also, there should be a minimum number of rating (i.e. at least 30 sample sizes) in order to be included and reflected for the set.
also, you can include weightage of certain raters, primarily because of the profile of the raters. For example, members who contributed a minimum number reviews can be categorized as "Serious AFOL" and their ratings will carry more weight. vs common fans (like me who is a serious fan of Lego but lazy enought to write a review!). However this will mean an additional project for you Huw, in order to categorize fan (some categories - " Newbie", "Collector", "AFOL, "Serious AFOL", "Really Serious AFOL" etc etc etc. :)
@Knoose said:
"Would switching to a 10 point system instead of 5 help add the missing granularity? This way the 3/4 star ratings would become a 5 - 9 rating."
(Tried to reply to this earlier but for some reason it didn’t show up.)
Basically, changing the scale and converting the existing ratings to the new scale will not change the shape of the curve. One other point, note that the scale is 0-5, so what does a rating of 3 become in a 0-10 scale?
Don’t round the figure, so people rate 1-5 but the average rating may be 3.45 or whatever. It maintains the 3 average but adds more range to distinguish between low 3’s and high 3’s.
What about rating being expanded to be multifactor and have an aggregate? A set could be rated on the minifigs, the build design, the build experience, etc. Then you could do searches on things like Star Wars sets over 300 pieces with the highest rated minifigs, things like that.
@lampstand said:
"One way is to have reviewers rate the set based on a set of criteria (which the system has now) on a scale of 1 to 5 (with meaning assigned to each number to for each criteria, to guide the reviewes i.e. what does a 1 in Playability criteria means vs a 5 in the same criteris), and then amalgamate the ratings of each criteria to arrive at a consolidated rating. Use should not rate overall rating without rating the individual criteria."
Who gets to decide what the criteria are, and the weighting of these criteria? (OK, we know the answer is that Huw is the ultimate arbiter.) Each person has different weights— build vs presentation vs playability etc. so how do you account for that? The entire problem is trying to assign a single number, or even a small set of numbers, to an entirely subjective rating.
I think I’m basically saying don’t make any changes, but document how the ratings are calculated.
I have a suggestion to motivate people into writing more reviews.
On the "Random set of the day" posts, we see several comments that are basically reviews.
After someone submits a comment, you could show a message:
Do you own this set?
- Help others by writing a new review »
- Use this comment as a review »
When the person press the second link, their comment is saved as a review draft and they are redirected to the draft to complete it.
There are some great suggestions above, and in a sense the system seems fine to me the way it is currently. I might offer a thought on the nature of the problem:
Reviews and ratings are inherently subjective per the preference of the individual that scored any given set. However, the framework of a rating system implies a degree of objectivity where a 5-star set is "better" than a 4-star set. Lots of scores can help show which sets are perceived as "better" and "worse" by a majority of the community, but if we all agreed on the particular ranking of every single set there would be no reason to rate them in the first place.
One response would be to use the ratings as a starting place for newcomers to the hobby, I think most sets that have 5 stars deserve them and would help out those who don't know what they want to experience in a LEGO set.
Another response is to rate sets for your own personal reflection, at which point it is still subjective but now all the ratings are based on one metric. Here the rating becomes more of a review: "This set is a 4/5 to me"
So the question isn't as much about how to score a set, but why? To me it is more personal, though there is merit in having a majority of the community in agreement about Modular Buildings being among the best of LEGO's products but also calling the company out when the occasional poor design hits the shelves.
I think there should be a 10-point system. Either 10 stars or five stars and you can give 1/2 of a star. Heck, make it 10 stars in 1/2 star increments.
Oh, and I'd add "set is in the top/bottom X% of all Lego sets/sets released that year/theme so we'd get an idea if it's a good set relative to other sets we might be interested in.
Quick usability feedback: on mobile, I often rate a set accidentally just by touching the rating box to scroll. Then I go back and un-rate, but I suspect I'm not catching every time it happens. Multiply that over thousands of users, and I suspect you may be seeing a bit of noise from mobile browsers.
I agree with everything @derekthetree said way up top. But, really, I’m not sure the ratings are really useful to anyone. I guess like many things one shops for online, a low rating might be cause to look more closely before purchasing, but I don’t do that for lego.
I am opposed to the change of allowing private ratings count toward the overall rating. I'm not angry, I don't think Brickset is ruined, I just feel like the decision is misguided, for a myriad of reasons.
Ironically, the single click arguably holds even more clout than written reviews which can take hours to write. That is because they are able to go unchallenged, while reviews can be marked as helpful and unhelpful, which unfortunately can be abused.
I think it's kind of unfair if someone goes to the trouble of writing a review, then people abuse the "Mark review as unhelpful" simply because they disagree with your opinion, even if the review is well-written. Then the reviewer's star rating is effectively silenced if enough users abuse the "unhelpful" option. Despite the fine-print saying "Rate whether you found it helpful, not whether you agree with the reviewer's views." it seems enough people have abused this function to
"vote" for or against a review, enough to in some cases undermine the review system.
I experienced this myself with my review of 9442-1 Jay's Storm Fighter. It is my only review, but I felt compelled to write it because I noticed serious flaws with the model which could potentially cause long-term damage to the pieces. However, because some other users got angry at my criticism, more of them rated my review as unhelpful than helpful.
It also seems kind of unfair to me that now anyone can casually rate a set and cause an impact without having to engage their brain by writing. If you write and really think about something, your own opinion might change, and be less biased and more objective.
Yet another potential for abuse is the infamous internet practice of "review bombing" coming to Brickset. Similar to the aforementioned abuse on rating a review unhelpful because you have a different opinion. Since you don't even need to own a set to rate it, I foresee users leaving lots of one-star ratings on sets, even as soon as they are revealed, just because for example they hate the movie it's based on or are salty about and Ideas set "stealing the place" of another.
I do concede that there is the benefit of having more people's voices heard, and get more representative figures. However, I believe to minimize abuse and continue to encourage review writing, star-only ratings should have a featherweight impact, such as counting as 10% of a full written review. At the very least, rating a review as unhelpful should not exempt it from affecting overall the star rating, or the function should be removed altogether given the ratings can be a bunch of review bombing, which is also inherently unhelpful but unable to be challenged like a written spam review.
Why does all this matter? We have a reputation to uphold as the largest remaining fan-run Lego website after Bricklink's acquisition. The Brickinsights review aggregator pulls data from Brickset set ratings. We have a responsibility to maintain credibility. Thank you for reading this comment.
I had to respond for 2 reasons. First I completely agree users rate reviews that are critical of a set as unhelpful. Believe that’s the case with my review of old fishing store....
2nd. I just happened to give my son the very set you mentioned this morning because it had been for sale in my bricklink store for 2 years at $11 and no interest. Crazy coincidence. Side note: he seemed to enjoy the build and In particular the open/closing of the wings which I totally think could eventually damage the parts.
@Norikins said:
" I experienced this myself with my review of 9442-1 Jay's Storm Fighter. It is my only review, but I felt compelled to write it because I noticed serious flaws with the model which could potentially cause long-term damage to the pieces. However, because some other users got angry at my criticism, more of them rated my review as unhelpful than helpful."
Maybe look at the Imdb.com system of rating. It works pretty well for them and the biased extremists generally cancel each other out leaving a balanced final rating.
Thank Huw for writing this article.
My 2 cents:
Similar to AppStore rating, a 1 to 5 scale is actually a 0 to 4 scale, because of the offset by 1. In this rating scale, '3' is a just pass (average) while '4' is a 75% percentile score (not 80%).
One problem is that Brickset does not have a critical mass of ratings for most sets. Unlike the AppStore, which keeps reminding users to rate its apps.
Maybe can add an option of Like/Dislike (thumbs up/down like Youtube)?
So first let me say I am a math major, and I nearly failed 300-level statistics (although I eeked out a D- which is passing).
The fact that you got a perfect bell curve when you take only sets with 10 or more rankings is proof that the methodology works when you have a large enough sample to pull from.
The location of the bell curve is irrelevant however. Imagine if you were a doctor and you decided to graph patient’s temperatures on a scale that went up to 105. The peak of the bell curve would be at 98.6, not at 52.5 (unless you specialize in extreme hypothermia). Likewise, it is the job of Lego employees to produce good sets. If Lego was constantly producing sets that got a ranking of 1 or even 2, no doubt they would go out of business and none of us would ever want to visit this website.
Changing the system to scale of 10 absolutely would not work as it would be equivalent to throwing out the million rankings you have already accumulated. You can’t transfer a 5 to a 10 as the user who granted the 5 may actually want to give it a 9, or even an 8, but felt that it was better than just a 4 on the scale of 5. Likewise a current 3 may translate to a 7 as a 3 is like assigning a grade of a C, but in school a C is associated with 70-79%. Changing the scale completely changes ones point of view. As you can see, changing the scale would be like starting from scratch. And quite honestly the bell curve would probably center around 7.
I would be more open to the idea of half stars as it wouldn’t change the scale any and that awesome set that is you just wish had that one extra minifigure could get a 4.5 while that set you can’t live without gets the 5. I don’t believe that adding half stars would change the way people viewed a 3, 4, or 5, but rather just allow them to refine their ranking. However, this isn’t really necessary as you already have that perfect bell curve.
I highly recommend against softening the score, basically what you are doing is giving every set a single 2.5 star review. That limited edition gold minifigure really does deserve 5 stars, it shouldn’t have a 3.75 ranking because only one member on Brickset owns it, there is a reason why it sells for $1000 on the second hand market.
So how do you make these rankings meaningful? The same way Amazon does, show the ranking based out of 5 stars, and in parentheses next to it show the number of people who assigned it a ranking. This way that super rare set that is awesome but impossible to get is still ranked a 5, but we know that only three users actually ranked it. If I’m buying say a toaster oven on Amazon and the choices are one that has 5 stars but a single review, or one that has 4 stars but 5000 reviews, I’m going with the 4 star toaster, even if it costs more money.
Ignore my ratings; I use the 5 star options to expand my organizational schema!!!!
I'm wondering what the basis for a rating would be? Regardless if it is a 5 star or a 1-10 scale. There are no categories like piece count or the rarity of pieces in a set. So people will rate a set totally uncategorized, e. g. a Star Wars fan might rate a Star Wars set higher then an Architecture fan. A vintage train/city fan hardly rate a Technic or Star Wars set. And as others mentioned, the 5 star rating is sometimes misused for other purposes like individual organization of a collection or wanted list.
Whether system is used, it might be worse to find out why someone gives 3, 4 or 5 stars for a set?
I personally combine the stars with the number of people who gave it.
Even one or two add more value than none.
I Will only gave the last one less weight myself.
Leaving info out, sours it a bit for me. Just provide ratings and number of people who gave it. You can Always make a hover function that displays the BSet weighed one.
Nearly every set I've rated has been because I accidentally pressed on it while scrolling on my phone...
I usually spot it and remove the rating, but I haven't checked for the ones I haven't noticed, if you know what I mean.
So how many were made on purpose vs by accident?
Rating .... By accident .... On purpose
5 ........... 6 ...................... 1
4 ........... 4 ...................... 0
3 ........... 6 ...................... 0
2 ........... 16...................... 0
1 ........... 3 ...................... 0
4000026 LEGO House Tree of Creativity was rated 2 by accident. It's one of my favourite sets.
31062-1 Robo-Explorer is the only set I've rated on purpose. I've even reviewed that set, which is the only set I've reviewed on here, of course.
Statistically speaking, each set will have a 'real rating'. This is the overall score that a particular set would have had, were all Brickset members (or indeed all AFOLs) would have rated that set. We could say this is 'the population'. The ratings that are currently recorded on Brickset are a subset of all possible ratings for a set, and thus could be regarded as a sample of that population.
Some of your samples are small (< 10 ratings), other samples are much larger. We know from Central Limit Theorem, that sampled data will tend to approximate the normal distribution if we draw enough samples and each sample is sufficiently large. The data shown (second graph) is a normally distributed as it comes (giving a very nice demonstration of the Central Limit Theorem). You mention the data is "skewed to the right". However, "skew" is actually a term to describe whether the normal distribution has one tail that is longer / fatter than the other. Your graph is pretty symmetric, so it looks there is no issue with skew (or kurtosis, which is another factor). You could say the distribution is 'shifted to the right', which would be a more objective explanation (but as someone else has suggested, irrelevant in statistical terms).
To go back to your question. Why are ratings of smaller sample sizes not normally distributed? So, if samples are too small (N <= 5), then it will be difficult to get to normality. Your suggestion of softening the data will indeed make the distribution more normal, but it actually does that by adding a constant to the data, and thus creating more noise. If anything, I would say that the softened data will be a more biased estimator (of the 'population's true score') than the raw scores. If you are worried about this, then you could always require a minimum number of ratings before ratings are published.
Like @omnium I don't think I've ever rated a set on purpose outside of a review. It's very easy to rate by accident while scrolling.
There seems to be a few logical fallacies in the math presented above. While it is true that Lego produces consistently high quality sets, there has to be some degree of variation among those, no matter how much we all like and adore Lego. Replace Lego with any other brand (let's say Lamborghini, and among Lamborghinis all of which are quality cars, there are stand out favorites) and this I think is the data you are trying to get to.
To do this, you have to also factor in the user doing the review. If someone only ever gives 4 stars and nothing else then any system would obviously predict that the next set they review would also be a 4. While you want to say that the reviews are functions only of the sets and their quality they are intrinsically biased by the reviewer. So, to compensate for that you would include some sort of weight assigned to the reviewer. If they never give a 5, but then do so for one set, that is an outlier and either is really great and impressed them or it was a mistake, either way - valuable data.
You'd probably want to include some representative value in your algorithm that says "User X has reviewed 1000 sets with an average rating of 4.3 and has deviated from the general consensus of the set by the general population by 10%," so that you know this person is a good reviewer that generally agrees with the masses and uses a statistically valid array of ratings available to him from 1 to 5 stars and has done so for X number of months (generally accounted for by the number of reviews submitted).
It gets complicated but it is doable and I think the population density of data nerds on this site would be as good a place as any to really tackle the star-averaging problem.
Thank you everyone for your input. It's very interesting.
It sounds as if there are two potential solutions:
1.
- Remove the softener
- show ratings only when there are more than 10
- Show the number of ratings next to the stars
2.
- Take a look at the Bayes estimator formula and see what that achieves
And, if possible,
- Prevent accidental ratings on phones
I agree reviews are preferable to simple ratings but unfortunately very few are contributed nowadays. I do like the idea of adding a 'review this set' to the RSotD articles, which might help, and to answer the question of what happened to the member review of the week, I've paused it while we do the gift guide and will also do so during December when we'll be doing the Advent calendars. So, it'll be back in January.
Some thoughts:
– if we don't have "average" 3-stars-ratings for most of the sets, how would you distiguish a very good set that get's almost 5 stars from an excellent set like Ninjago City that also gets almost 5 stars?
– would it be useful to decouple the input (5 steps are fine grained enough for a single vote) from the output (0-100% steps) to differentiate better?
– would it be useful to visualize the popularity somehow? Like ... both sets have a rating of 90% and are lets say "green", but the more saturated the displayed rating is (or the bolder the font is), the more "weight" it has supported by many results? And the more bland (or thin) it is, the less popular, despite the good rating? This must not be too complicated in the visualization, but we have two dimensions of input (Quality and Quantity), so having two dimensions in the output make things transparent instead of mixing them into one output value by some formula.
– how about showing two ratings: those from the reviews (with effort and thought) and those from the single-click stars (less thought but more data)?
Interesting topic.
Reviews and scores are always going to be subjective, and for user reviews they're always going to be skewed by a number of factors.
Firstly, if someone's reviewing a set then it's highly likely that they've bought the set with their own money, or at the very least, chosen it. So it's a set that already appeals.
Secondly, as others have pointed out, Lego aren't in the business of turning out duff models. Sets like the 42113 Technic Osprey, which, if the available evidence is to be believed, was as likely to have been pulled because of a design fault as it was the 'controversy' over its links to the military, are few and far between. So any 'dislike' of a set is going to come down to an individual not liking the colour scheme / design / range of the set, which would almost certainly have precluded them from buying it in the first place.
So high(er) scores are inevitable from users. That's why I always give more credence to the 'official' Brickset reviews which look objectively at sets supplied by Lego. I've only ever bought one set that I was really disappointed with - the 42111 Technic Dodge Charger - and if I look back at Huw's review, he was really disappointed too.
For me, then, the value of a review is in the text, not the number at the end. If I can understand *why* someone liked - or didn't like - a set, then I can decide for myself if that's important. If they knocked it down a star because they didn't like the colours, but those same colours appeal to me, I'll mentally bump the score up.
Edge, the videogaming magazine, rates games out of 10, and some years ago ran an issue where they omitted the scores, meaning that people had to read the text and make a decision for themselves. Their postbag the following month was stuffed to the gunnels, with half the correspondents loving the change of approach and half wanting their precious scores back.
Bottom line, there's no perfect system. You just give as much information about a set as you can - text, scores, images - and let the reader decide.
Caveat Emptor!
I absolutely adore this question. I love the lively feedback, and then to see it in real time spark Huw’s response for how to make improvements: what a phenomenal community and Huw what an amazing site you have created and continue to advance!
@alfred_the_buttler said:
"Everything correctly"
In addition to that, as a physics teacher, I can also assure you that switching to a 10 point system would do nothing. And that's because of psychology, not math.
1) In a 10 point scale people associate 1-5 with bad, 6 passable, 7 average. So switching from a 5 point scale to a 10 would only help you better distinguish between the now rated 1-2 sets.
2) Rating is highly subjective. To the point that the same teacher will grade the same essay with up to a 2 point difference 6 months later on a 5 point scale. That is huge. The point is that there's no point in granulating the system even more when it's already so arbitrary.
The fact you get such an amazing Bell curve of your ratings really only means your system works very well and the outlier ratings get drowned out by all the other ones.
What I get the feeling is troubling you is data representation. But that is a whole other topic that I believe deserves an article on its own :)
I've changed the calculation to remove the softener. Ratings won't be shown for sets with fewer than 10, and tomorrow I'll upload code to show the number of ratings next to the stars. At the moment it can be seen as a tooltip on the stars.
My 2 cents. I think were are missing the point with the rating system. I see the purpose of the rating system as two things: 1) provide a quick gauge of the opinion of the set from the Lego community in general. 2) increase community engagement.
As it stands the rating wasn't doing either of those things particularly well. I have ignored the ratings for sets because it is based on a very small number of reviews that didn't get downvoted. This means it didn't tell me anything I wouldn't know from glancing at the reviews and I would like to hear what the community in general thinks, not just the curated reviews.
As for engagement, I didn't touch the rating stars for 5 years because they didn't count for anything. I only started now because they might in the near future. And I LOVE rating things and then analyzing which are the highest and lowest rated and why.
I agree there should be a minimum number of ratings before they show up on the set, but I don't think it matters that there are a lot of sets around 3-4 stars or that some might down vote a set. The point is to see how the community feels about a set. Heck, you might get more reviews if people feel the need to defend a set the think has been unfairly rated.
I believe there should only be four options to chosen from for rating:
strong dislike (0) - dislike (1) - like (2) - like very much (3),
e.g. no average rating to select. Then you would be forced to make up your mind.
If I cannot make up my mind I always add the value-for-money (would I buy again?) as criterion for rating.
Of the 404 unique sets that I manage within my account I selected a rating for 96 of them:
1 - 5x
2 - 9x
3 - 34x
4 - 34x
5 - 14x
which, I think, resembles the curves calculated by Huw.
I have little interest in completing the rating - it would likely add to the lower ratings.
Would it be difficult to show both ratings?
I think the modified rating should be more like a ranking/popularity than a rating and that rating should be whatever the unmodified average is.
@datsunrobbie said:
"Would it be difficult to show both ratings? "
I think this is a good idea.
Personally, I use ratings to set the order of sets on my wanted list, and make it so that certain sets show up first when I search for a part, tag, or minifig (I have my 'Sort by' set to 'Your rating (desc)'). Is there another way to do these things? Otherwise, there are probably others doing the same thing as me, which might skew the ratings data.
These are some of my favorite type of articles on this site. Love seeing the background thinking and the desire to make the site even more helpful to the fans of Lego. Way to go, Huw!
Perhaps you could use the review scores to give each set a percentile rating - e.g. top 2%, top 15%, bottom 30%, etc, etc.
This way you'd have a much bigger scope to distinguish between the sets rated closely in the middle (I.e. they become comparative ratings rather than absolute ratings).
It would also be really cool to see a list of the top sets, a bit like on IMdB where you can see the top 200 movies ranked in order.
Excellent site by the way, I really enjoy it as a fan of lego and also of databases and statistics!
^ There's a query to show just that: https://brickset.com/sets/query-32
There's a reason it's called the normal distribution ;-)
As others have said, I don't really mind that most sets get a 3-4 rating, it's what you'd expect. You can stretch the curve and make the ratings go to 10 (or even all the way up to 11 you know ;- ) but that won't change the relative scores. However the damper that gives a single 5 star review a lower score than 10 5 star reviews seems fair.
What bothers me more (and this too has been mentioned by others) is the helpful vote. Indeed I noticed years ago that critical reviews, especially of Star Wars sets, get more 'unhelpful' votes. It's really frustrating when you've spent an hour writing a review explaining why the set isn't great and it's voted 'unhelpful' while a two-line 'this is fantastic' review is voted helpful.
Can't say I have a solution for this problem though....
I run a web site that lists conventions. People can mark cons they've been to and rate them. I don't even display the ratings for cons unless at least 5 people have rated them because I don't want something showing up with a rating of 1 or 5 stars just because one person says so.
Unfortunately, the site doesn't have a ton of people rating the cons they've attended. I had hoped to put 10 as the minimum number of ratings before it's displayed, but there's far fewer cons that have had 10 or more people rate them.
Since I'm rating conventions and only people that have attended the cons can rate, I give different weights to ratings from different badge types people (claimed to) have. A regular attendee is weighted at the middle of the road...but someone attending as press has their rating count more, but someone who was actually staff at the con has their rating count much less (because of likely bias in their rating).
In my ratings, I'm seeing most people giving everything 5 stars as if everything is awesome. ...and then there's some that just want to hate and do 1 star. I'm working on implementing a weighted system so that if you're just going and rating everything as 4 or 5 stars...or everything as 1 star, your rating won't carry as much weight as someone that has a more even distribution of ratings. Also, the more you rate, the more weight your rating will carry. It'll be some complex calculations, so I'll have it just calculate it once a day rather than on page load...which would also discourage people from changing ratings just to see how their individual rating can affect the overall rating.
Prior to a site redesign, I used to display text when people hovered over the stars used to rate. It would say something like, "1 - Terrible", "2 - Poor", "3 - Average", "4 - Good", "5 - Perfect!" That was an attempt to help people understand that 5 was intended to be perfect and not just "good"...and that if a con was just okay, 3 might be the best choice. It didn't make it into the new design because...uh... I guess I was lazy.
@Huw said:
"^ There's a query to show just that: https://brickset.com/sets/query-32"
I looked at what comes up at the end of that query and it's stuff with no rating. You may want to change
SELECT * FROM sets WHERE (Theme 'Gear') ORDER BY WeightedScore DESC
to be something like
SELECT * FROM sets WHERE (Theme 'Gear') AND WeightedScore > 0 ORDER BY WeightedScore DESC
...so that anything with no score isn't in the results.
Once you guys figure this out, please let me know as the 5-star ratings I use on my own site are pretty darn deceptive. Thanks, Jeff.
@alfred_the_buttler said:
"So first let me say I am a math major, and I nearly failed 300-level statistics (although I eeked out a D- which is passing). "
I was not a math major, and I hated my engineering stats class :-)
"I highly recommend against softening the score, basically what you are doing is giving every set a single 2.5 star review. That limited edition gold minifigure really does deserve 5 stars, it shouldn’t have a 3.75 ranking because only one member on Brickset owns it, there is a reason why it sells for $1000 on the second hand market. "
No. If you look at the formula, the 2.5 is divided by the number of ratings. The softening bias essentially is a way of “rounding” scores, and plays less and less a role as the number of ratings goes up.
The softening only makes sense if there are enough ratings. Not revealing the score unless there are “enough” ratings seems a reasonable way to handle this. If the scale is changed, the softening factor should also be scaled. If you’re worried about the effect on a 0-5 scale, maybe choose a smaller number, e.g. 1.25?
@Huw regarding
"Softened ratings were shown until I was persuaded to revert to unsoftened ones few years ago. I can't remember why now"
see https://forum.brickset.com/discussion/15625/ratings-revisited
^ Thank you. I remembered it has been discussed somewhere but not where!
I rate all my Star wars sets. I like almost all of do hem, my ratings are usually from 4 to 5, mostly 5. Only sometimes I give 3 stars.
If there were 10 stars, I will give them from 6 to 10 stars, mostly 8 or 9. 0nly some will get 5 or less stars ...
@aamartin0000 said:
" @alfred_the_buttler said:
"So first let me say I am a math major, and I nearly failed 300-level statistics (although I eeked out a D- which is passing). "
I was not a math major, and I hated my engineering stats class :-)
"I highly recommend against softening the score, basically what you are doing is giving every set a single 2.5 star review. That limited edition gold minifigure really does deserve 5 stars, it shouldn’t have a 3.75 ranking because only one member on Brickset owns it, there is a reason why it sells for $1000 on the second hand market. "
No. If you look at the formula, the 2.5 is divided by the number of ratings. The softening bias essentially is a way of “rounding” scores, and plays less and less a role as the number of ratings goes up.
The softening only makes sense if there are enough ratings. Not revealing the score unless there are “enough” ratings seems a reasonable way to handle this. If the scale is changed, the softening factor should also be scaled. If you’re worried about the effect on a 0-5 scale, maybe choose a smaller number, e.g. 1.25?"
You are stating my point exactly. The softening does next to nothing as a set accumulates many reviews. But a very limited edition set that only has a single review gets its rating destroyed. Having a single review doesn’t make it a bad set, in this scenario it is just very difficult to obtain the set, but maybe well worth the investment.
Let’s say you apply a softener to rankings of cars. The 2020 Toyota Corolla gets an average score of 3.9 from over a million people who own it, the softener is irrelevant to its score. The 1950 Studebaker Ice Princess has a single 5 star review, apply a softener of 1.25 as you suggested and it’s rating is 3.1. Is the Corolla really the better car? From a practical point of view it probably is, but you can’t honestly tell me that you wouldn’t want to have an Ice Princess sitting in your driveway making all your neighbors jealous!
Softening does not round scores, it simply punishes hard to find sets or sets that people aren’t interested in.
That said I also disagree with requiring a minimum count before displaying the ranking. Although it does make sense to require a minimum number of reviews to appear on a leaderboard. Think of it like a baseball player. A one-time September call up gets a single at bat and gets a hit. He has a 1.000 batting average. He does not deserve to win the batting title as he does not have the 400 plate appearances necessary to be on the leader board. But he absolutely has the right to brag about his 1.000 batting average for the rest of his life and display the ball proudly above his mantle in the same way you display that incredibly rare Lego set.
The fact that reviews tend to sit around 3-4 is more to do with human perception of ratings, I think, in a manner similar to the three point scale in game reviews - nearly all games that actually run and don't make the player violently ill get at least a 7. There's a minimum standard of functionality that gets you those first two or three points in most people's minds, regardless of whether that quality is omnipresent for that kind of product, and it's quite difficult to get people to stop thinking that way.
I think that it makes sense to only allow a rating to have weight if the person has actually built the set. To me it would make sense to allow everyone to rate any set, but only users who own the set should have their ratings count toward the set's overall/average rating.
"Should ratings be more evenly spread between 1 and 5, or should the majority of sets just be rated mediocre?"
I think this is a misinterpretation of the data - the reality is more nuanced and twofold...
1. Most LEGO sets are pretty decent - this is the result of many years experience creating great products, which includes playtesting, market research, etc...
2. Even with a narrow distribution like this, there's plenty of room for the best sets to rise to the top and the worst to fall to the wayside. It just happens that the numeric difference between a top 10% set and a bottom 10% set is only 2/5 stars, after averaging many reviews together.